지도학습-분류
데이터 분류
결정 경계 g(x;Θ)를 얻는 두 가지 접근법
- 베이즈 분류기
- P(Ck | x)를 추정하여 분류
- 베이즈 분류기
- 데이터 기반 방법
- 데이터 간의 관계를 바탕으로 분류
- K-최근접이웃 분류기
베이즈 분류기
- 클래스 별 확률밀도
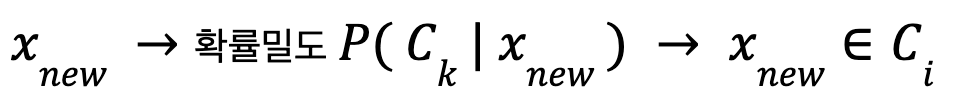
이진 분류기 (클래스가 2개인 경우) p(C1) = p(C2)
x가 각 클래스에 속할 확률 P(C1|x), P(C2|x)중 확률값이 큰 클래스로 할당하는 방법
각 클래스에 대한 확률분포함수를 미리 가정하고 추정함
학습 데이터를 통해 평균과 표준편차만 계산하여 활용함 (분류 과정에서 학습 데이터가 불필요)
판별함수 :
g(x) = P(C1|x) - P(C2|x)
베이즈 정리
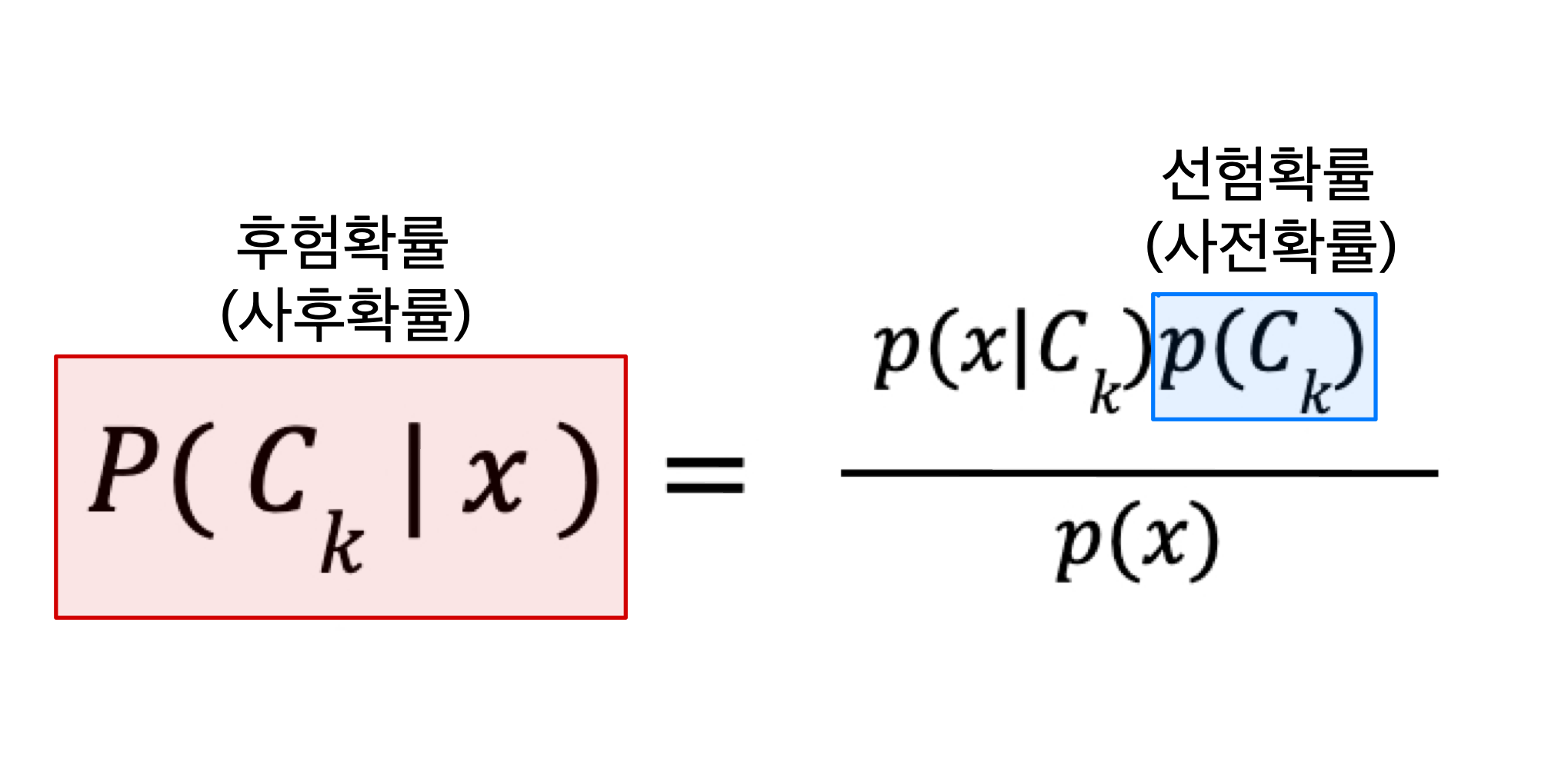
결정경계

결정규칙
K-최근접이웃 분류기 (K-NN 분류기)
클래스와 상관없이 모든 데이터 중에서 새로운 데이터와 거리가 가까운 순서대로 K개의 데이터를 뽑았을 때, 개수가 더 많은 클래스에 새로운 데이터를 할당하는 방법
확률 분포 모델을 미리 가정하지 않고 데이터 집합을 이용하여 추정함.
새 데이터가 주어질 때마다 학습 데이터 전체와의 거리 계산이 필요 (항상 학습 데이터를 저장함 -> 비용 증가)